Linked Reads
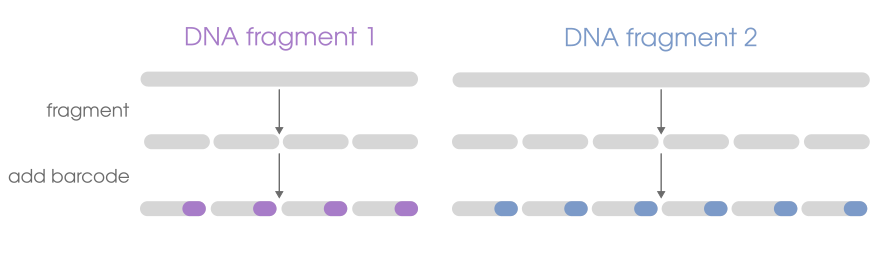
Linked reads are short-read (e.g. Illumina) data. What makes them different from other kinds of sequencing data
is that they contain an added DNA segment ("barcode") that lets you associate
sequences as having originated from a single DNA molecule. That means 4 sequences that all contain the same linked-read barcode
can be inferred as having originated from the same original DNA molecule. Different barcode = different molecule of origin.
If the sequences with the same barcode would map near the same genomic region during sequence alignment, we would know that
each of those reads originated from a single DNA fragment from a single homologous chromosome from a single cell, which is effectively built-in phase information.
What do they look like?
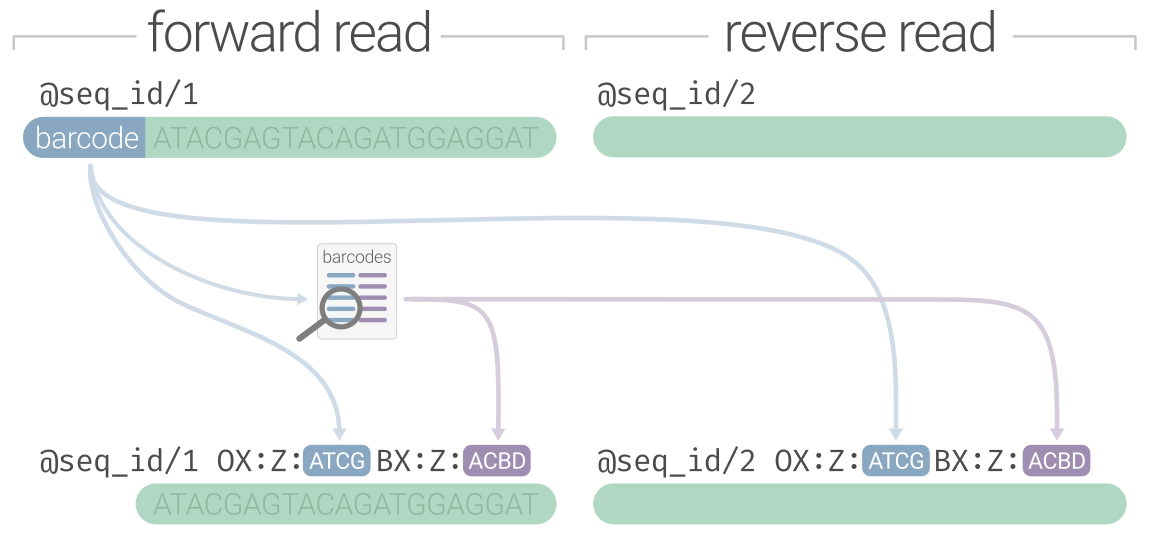
Linked-read sequence data appears as you might expect it, encoded in a FASTQ file. The first processing step of
linked-read data is demultiplexing to split the raw Illumina-generated batch FASTQ file into samples (if multisample)
and identify/validate the linked-read barcode on every sequence. For 10X data, the barcode would stay inline with
the sequence (to make it LongRanger compatible), but for other varieties (haplotagging, stLFR, etc.) you would also
remove the barcode from the sequence and preserve it somewhere in the read header. The demultiplexing process
is generally similar between non-10X linked-read technologies: a nucleotide barcode sequence gets identified and moved from
the sequence line to the read header with some kind of platform-specific notation. The diagram below preserves the nucleotide
barcode under the OX:Z tag and recodes it under BX:Z using the haplotagging "ACBD" segment format, however it would
also be valid to just keep the nucleotide barcode under BX:Z. Linked-read software is variable in its flexibility towards barcode
formatting.
Linked-read varieties
There are a handful of linked-read sample preparation methods, but that's largely an implementation detail. All of those methods are
laboratory procedures to take genomic DNA and do the necessary modifications to fragment long DNA molecules, tag the resulting fragments with the same
DNA barcode, then add the necessary Illumina adapters. It's not unlike the different RAD flavors (e.g. EZrad, ddRAD, 2B-rad)-- they all give you RAD data in the end,
but vary in how you get there in terms of cost and bench time.
Always Usable Data
Unlike some other sample preparation methods (cough cough mate-pair), linked-read data is whole genome
sequencing (WGS). What that means is that whether you use the linked-read information or not, the data will always be standard and
viable WGS compatible with whatever you would use WGS for. It's WGS, but with a little extra info that goes a long way.
Standard / LASTQ
The Standard (LASTQ) format guarantees BX:Z and VX:i SAM tags that encode the barcode and it's
validity. This format is universal and agnostic to all existing linked-read varieties and their particulars.
It is 100% compliant with comment transfer during alignment and trivial to parse once in SAM format.

This format makes it the responsibility of the early data processing software
(as early as demultiplexing) to encode the data in this format for downstream
processing. Our hope is that this flexible htslib-compliant format gets widespread adoptions to reduce
the fragmentation in the software ecosystem and reduce the need for file format
conversions. It also creates a blueprint for a generic file encoding for any new
linked-read methods that are being developed or can be developed in the future.
Specification
-
BX:Z tag to record the barcode, the format of which is irrelevant
- it could be haplotagging
ACBD, stLFR 1_2_3, nucleotides, whatever
-
VX:i tag to record if the corresponding barcode is valid
| VX tag | tag value | definition |
|---|
VX:i:0 | 0 | barcode is invalid |
VX:i:1 | 1 | varcode is valid |
-
Uses older CASAVA format (/1 or /2) to identify forward/reverse sequence
- suffixed at the end of the sequence ID, without spaces
- e.g.,
@A00470:481:HNYFWDRX2:1:2101:29532:1063/1
-
Comments are SAM TAG:TYPE:VALUE format and tab-separated see below
-
standard FASTQ naming conventions:
.fastq or .fq.fastq.gz or .fq.gz if b/gzipped.F or .R1 to indicate it's read 1 (forward read).R or .R2 to indicate it's read 2 (reverse read)- e.g.,
sample_1.R1.fq.gz
Despite the half-serious name LASTQ, standard-format files are FASTQ files and
their naming conventions should follow FASTQ conventions exactly.
FASTQ example
stLFR style FASTQ header with a valid barcode
@A00470:481:HNYFWDRX2:1:2101:29532:1063/1 BX:Z:45_11_361 VX:i:1
haplotagging style FASTQ header with an invalid barcode
@A00470:481:HNYFWDRX2:1:2101:29532:1063/1 BX:Z:A78C00B14D96 VX:i:0
SAM/BAM example
haplotagging style SAM record with a valid barcode
A00470:481:HNYFWDRX2:1:2229:29912:29778 99 2R 1222 40 19S80M = 1500 428 AGATGTGTATAAGAGACAGAGTTATGTCATTTTAAGCGGTCAAAATGGGTGAATTTCCGATTTCAAGTAATAGGCGAACTCAAGATACCTTCTACAGAT FFFFFFFFFFFFFFFFF:FFFFF:FFFFF:FFFF:FFFFFFFFFFFFFFFFF:FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF:,FFFFFFF:FFFFF NM:i:0 MD:Z:80 MC:Z:150M AS:i:80 XS:i:80 RG:Z:sample1 MI:i:1 VX:i:1 BX:Z:A55C67B91D96
nucleotide (TELLseq/10X) style SAM record with an invalid barcode
A00470:481:HNYFWDRX2:1:2229:29912:29778 99 2R 1222 40 19S80M = 1500 428 AGATGTGTATAAGAGACAGAGTTATGTCATTTTAAGCGGTCAAAATGGGTGAATTTCCGATTTCAAGTAATAGGCGAACTCAAGATACCTTCTACAGAT FFFFFFFFFFFFFFFFF:FFFFF:FFFFF:FFFF:FFFFFFFFFFFFFFFFF:FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF:,FFFFFFF:FFFFF NM:i:0 MD:Z:80 MC:Z:150M AS:i:80 XS:i:80 RG:Z:sample1 MI:i:1 VX:i:0 BX:Z:TACANNNCACAGAG
SAM Tag Specification
Valid SAM tags take the form TAG:TYPE:VALUE, which are discussed here in further detail. The official SAM spec for tags can be found here.
TAG
All SAM tags are 2 capital alphanumeric characters, like the BX in BX:Z. HTSlib has established standard definitions for some tags (see below), which means
you should not repurpose those tags or populate them with anything other than what the SAM spec has established them to be.
TYPE
All SAM tags require a single case-sensitive character to specify
what the data type is. The most common ones you will see are Z and
i (e.g., BX:Z, VX:i). For convenience, these are the SAM spec
type definitions:
| character | data type |
|---|
A | character |
B | general array |
f | real number |
H | hexadecimal array |
i | integer |
Z | string |
These are the tags resereved by the SAM spec and cannot be used for anything other than what they are described for.
This also means you cannot change tag types. For example, AM:i is a standard SAM tag, which means it cannot take
any other form like AM:Z, AM:H, etc. Even if a record does not contain an AM:i tag, adding any variant of it, in
terms of data type or the meaning of the value it encodes, is very likely to break compatibility with tools that read
SAM tags.
| TAG | TYPE | Description |
|---|
| AM | i | The smallest template-independent mapping quality in the template |
| AS | i | Alignment score generated by aligner |
| BC | Z | Barcode sequence identifying the sample |
| BQ | Z | Offset to base alignment quality (BAQ) |
| BZ | Z | Phred quality of the unique molecular barcode bases in the OX tag |
| CB | Z | Cell identifier |
| CC | Z | Reference name of the next hit |
| CG | B,I | BAM only: CIGAR in BAM’s binary encoding if (and only if) it consists of >65535 operators |
| CM | i | Edit distance between the color sequence and the color reference (see also NM) |
| CO | Z | Free-text comments |
| CP | i | Leftmost coordinate of the next hit |
| CQ | Z | Color read base qualities |
| CR | Z | Cellular barcode sequence bases (uncorrected) |
| CS | Z | Color read sequence |
| CT | Z | Complete read annotation tag, used for consensus annotation dummy features |
| CY | Z | Phred quality of the cellular barcode sequence in the CR tag |
| E2 | Z | The 2nd most likely base calls |
| FI | i | The index of segment in the template |
| FS | Z | Segment suffix |
| FZ | B,S | Flow signal intensities |
| GC | ? | Reserved for backwards compatibility reasons |
| GQ | ? | Reserved for backwards compatibility reasons |
| GS | ? | Reserved for backwards compatibility reasons |
| H0 | i | Number of perfect hit |
| H1 | i | Number of 1-difference hits (see also NM) |
| H2 | i | Number of 2-difference hits |
| HI | i | Query hit index |
| IH | i | Query hit total count |
| LB | Z | Library |
| MC | Z | CIGAR string for mate/next segment |
| MD | Z | String encoding mismatched and deleted reference bases |
| MF | ? | Reserved for backwards compatibility reasons |
| MI | Z | Molecular identifier; a string that uniquely identifies the molecule from which the record was derived |
| ML | B,C | Base modification probabilities |
| MM | Z | Base modifications / methylation |
| MN | i | Length of sequence at the time MM and ML were produced |
| MQ | i | Mapping quality of the mate/next segment |
| NH | i | Number of reported alignments that contain the query in the current record |
| NM | i | Edit distance to the reference |
| OA | Z | Original alignment |
| OC | Z | Original CIGAR (deprecated; use OA instead) |
| OP | i | Original mapping position (deprecated; use OA instead) |
| OQ | Z | Original base quality |
| OX | Z | Original unique molecular barcode bases |
| PG | Z | Program |
| PQ | i | Phred likelihood of the template |
| PT | Z | Read annotations for parts of the padded read sequence |
| PU | Z | Platform unit |
| Q2 | Z | Phred quality of the mate/next segment sequence in the R2 tag |
| QT | Z | Phred quality of the sample barcode sequence in the BC tag |
| QX | Z | Quality score of the unique molecular identifier in the RX tag |
| R2 | Z | Sequence of the mate/next segment in the template |
| RG | Z | Read group |
| RT | ? | Reserved for backwards compatibility reasons |
| RX | Z | Sequence bases of the (possibly corrected) unique molecular identifier |
| S2 | ? | Reserved for backwards compatibility reasons |
| SA | Z | Other canonical alignments in a chimeric alignment |
| SM | i | Template-independent mapping quality |
| SQ | ? | Reserved for backwards compatibility reasons |
| TC | i | The number of segments in the template |
| TS | A | Transcript strand |
| U2 | Z | Phred probability of the 2nd call being wrong conditional on the best being wrong |
| UQ | i | Phred likelihood of the segment, conditional on the mapping being correct |
10X
10X Genomics Linked Reads
The elder of the bunch and also a discontinued commercial product. 10X-style FASTQ files have the linked-read barcode
as the first 16bp of the forward (R1) read. For these data to be compatible with the 10X LongRanger suite,
the barcode must stay in the read. Moving the first 16bp into the read header breaks LongRanger compatibility.

Specification
- barcode is the first 16bp of the
R1 read
- barcode stays in the sequence data for LongRanger compatibility
- limited to ~4.7 million barcodes
Haplotagging
Unlike the other listed chemistries, haplotagging is a non-commercial (DIY) linked-read chemistry. Haplotagging barcodes are combinatorial and
are made up of four 6bp segments. Two of these segments ("A" and "C") are the first 12bp of the I1 read and
the other two ("B" and "D") are the first 12bp of the I2 read, both of which are provided by Illumina for standard sequencing runs.
Because of this segment design, there are 96^4 (~84 million) possible barcode combinations (~900,000 per sample).
The barcodes are stored in the sequence header under the BX:Z SAM tag, recoded in their "ACBD" format.

Specification
- 4 barcode segments
A segment is the first 6bp of the I1 readC segment is the next 6bp of the I1 read (7-12)B segment is the first 6bp of the I2 readD segment is the next 6bp of the I2 read (7-12)
- barcode stored as
BX:Z tag in the read header in ACBD format
- e.g.
@A003432423434:1:324 BX:Z:A45C01B84D21
- invalid barcode segment encoded with
00 (e.g., C00)
stLFR
Single-Tube Long Fragment Reads (stLFR)
Another of the presently available commercial linked-read options. stLFR data uses combinatorial barcodes
made up for three 10bp segments which are at the end of the R2 read. Demultiplexing these data results
in the barcode being moved to the sequence ID using a pound (#) sign between the sequence ID and barcode, with
the barcode recoded in the 1_2_3 format, where each segment is an integer.

Specification
- depending on the link sequence between segments, will be either the last 54bp or 42bp of the
R2 read
- 54 base barcode: 10+6+10+18+10
- 42 base barcode: 10+6+10+6+10
- barcode appended to sequence header with
# sign
- e.g.
@A003432423434:1:324#12_432_1
- invalid barcode segment encoded as
0 (e.g., 1_0_29)
- advertised to have a capacity over 3.6 billion, with up to 50 million per sample (actual results may vary)
TELLseq
Transposase Enzyme-Linked Long-read Sequencing
One of the presently available commercial linked-read options. TELLseq data is very similar to 10X, except the
barcode is 18bp long and contained in the I1 read that Illumina provides with the standard R1 and R2 reads. The
barcode gets appended in the read header using a colon (:).

Specification
- barcode is the first 18bp of the I1 read
- barcode is appended to sequence header
- e.g.
@A00234534562:1:544:AATTATACCACAGCGGTA
- invalid barcode contains at least one
N character
- advertised to have a capacity over 2 billion barcodes, but realistically use <24 million